Building a RAG System with LlamaIndex, Pinecone, and GPT-4

06 July, 2025 ・🕒 8 min read
As AI becomes increasingly accessible, we gain powerful opportunities to build intelligent assistants for specific, real-world problems. In my case, that meant helping university students get accurate, instant answers about academic procedures without relying on complex portals.
This article explains how I built AskUiz, a student assistant app powered by a Retrieval-Augmented Generation (RAG) architecture. It combines FastAPI, LlamaIndex, Pinecone, and GPT-4 to answer pedagogical questions about Ibn Zohr university.
Large language models (LLMs) like GPT-4 have revolutionized how machines understand and generate human language. However, despite their remarkable capabilities, these models are limited by static training data and can sometimes produce inaccurate or outdated responses. They don't inherently "know" your specific documents or data. (the MCP protocol does cover this limitation though)
And here comes Retrieval-Augmented Generation, which enhances LLM performance by integrating external knowledge sources into the generation process. The flow is simple:
- Index your data (PDFs, internal docs, web pages..)
- Retrieve relevant chunks based on user queries
- Feed that context into the language model
- Generate answers grounded in facts
Instead of relying solely on what the model has memorized during training, RAG systems retrieve relevant documents from a dedicated knowledge base and feed this information into the model to produce more accurate answers.
AskUiz is a practical example of this architecture, we have built it using the following stack:
Tech Stack
| Component | Tool |
|---|---|
| API Backend | Python + FastAPI |
| Embedding & Retrieval | LlamaIndex |
| Vector Store | Pinecone |
| Language Model | OpenAI GPT-4 |
| Rate Limiting | Redis |
| Frontend | Next |
| Deployment | Vercel, Render |
System Architecture
And here's a high-level overview of AskUiz's architecture:
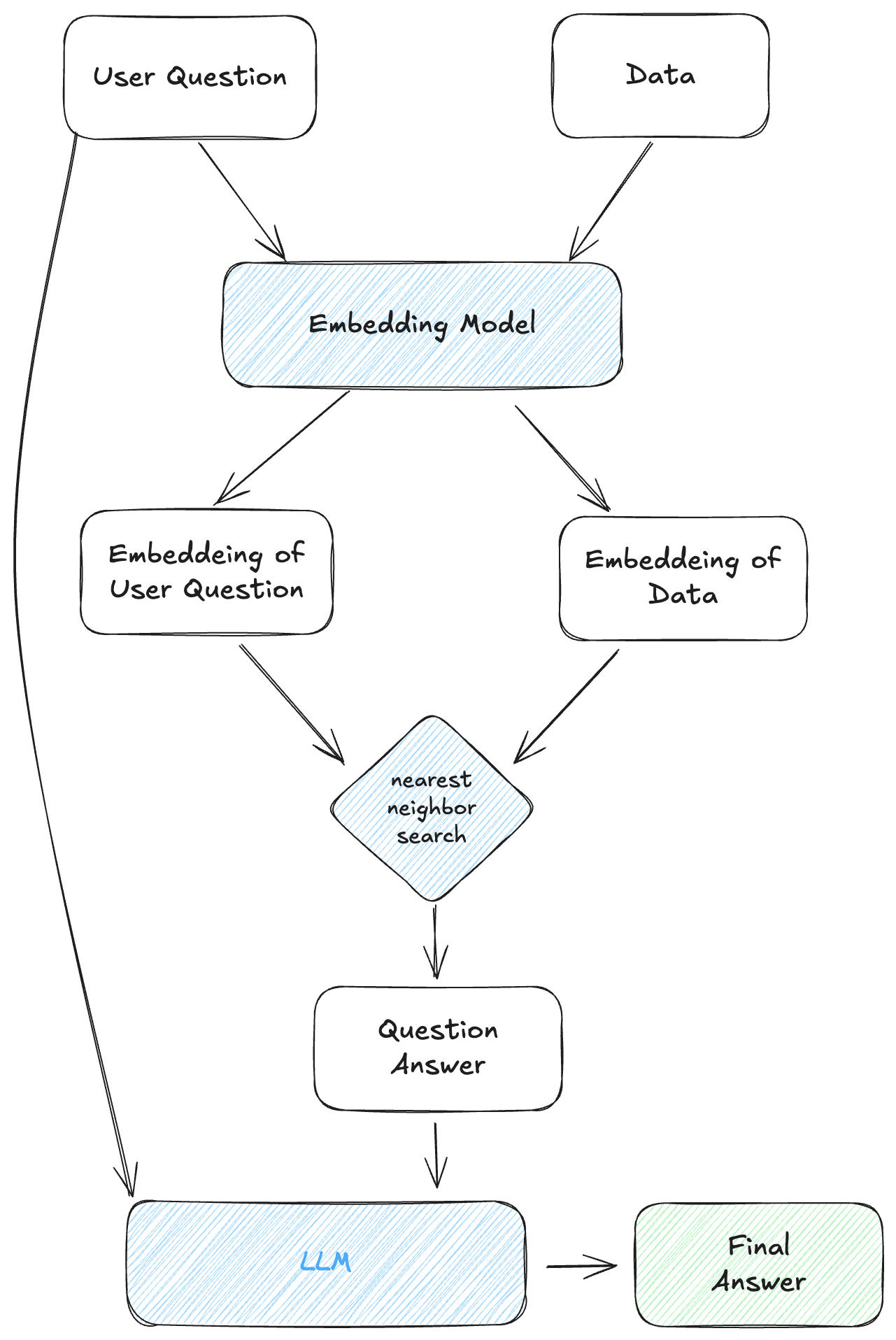
I leveraged Python's ecosystem with libraries like LlamaIndex for document processing, Pinecone for vector storage, and OpenAI's API for embedding and completion.
Data Collection and Preprocessing
The first critical step was gathering high-quality, domain-relevant data. For AskUiz, this included:
- Course and degree information
- Administrative procedures documentation
- Location and contact details for university institutions
- Services and student affairs information
Once collected, data preprocessing transforms raw content into a structured format suitable for embedding and retrieval:
The Preprocessing Pipeline
- Data Cleaning: Removing unnecessary characters, correcting formatting, stripping HTML tags, and standardizing encoding
- Chunking: Breaking documents into smaller, semantically meaningful segments (I used approximately 500 tokens per chunk with 50-token overlaps)
- Metadata Addition: Adding source information, document type, faculty, and other relevant attributes to each chunk
- Indexing: Converting content into fixed-size vectors using embedding models
I used LlamaIndex to manage document parsing, chunking, and routing embeddings to Pinecone for storage:
Retrieval from Pinecone
When a user asks a question like:
"How can I get my license diploma from ENSIASD?"
The retrieval process involves:
- Embedding the query using the same model used for documents
- Searching for the most semantically similar chunks in Pinecone
- Returning the top
krelevant pieces to use in generation
This ensures GPT-4 has real context instead of hallucinating answers based on general knowledge.
Prompting & Generation with GPT-4
With the relevant context retrieved, we build a structured prompt:
You are a university assistant for Ibn Zohr University.
Answer the question based ONLY on the context provided below.
If you can't find the answer in the context, say "I don't have
enough information to answer this question accurately."
Context:
- [Chunk 1 content]
- [Chunk 2 content]
- [Chunk 3 content]
...
User question:
"{user_query}"Then we send it to OpenAI's GPT-4 via the chat/completions endpoint:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt_with_context}
],
temperature=0.3 # Lower temperature for more factual responses
)The response is then parsed and sent back to the frontend. This approach grounds the model's answers in the specific documents we've provided, reducing hallucinations significantly.
Frontend Experience (Next.js)
On the frontend, AskUiz uses Next.js and TypeScript to:
- Send queries to the backend API
- Display GPT-4's answers with minimal latency
- Collect user feedback (e.g., helpful/unhelpful)
- Track usage with Vercel Analytics
The interface is mobile-first and responsive, designed to work well on campus or in transit. Since many students access the service via mobile devices, optimizing for smaller screens was a priority.
Rate Limiting with Redis
To avoid abuse and manage costs, I implemented IP-based rate limiting:
- Maximum 20 requests per day per IP
- Tracked in Redis with TTL (time-to-live) keys
This was simple to implement in FastAPI using dependency injection and provides sufficient protection for an MVP while keeping the service accessible.
Deployment
The deployment strategy keeps the system manageable and cost-effective:
- Frontend is deployed to Vercel
- Backend API runs on Render
- Pinecone and OpenAI are accessed as managed services
- The whole system is monitored with logs, analytics, and feedback mechanisms
Key Lessons Learned
- Quality over quantity. Well-curated data beats large volumes of irrelevant content.
- Prompt engineering is critical. The same data with a better prompt returns better answers.
- Rate limiting matters. Even MVPs need basic protection against abuse.
- Tool selection is important. LlamaIndex + Pinecone + GPT-4 proved to be a powerful combination for RAG.
- Users prioritize clarity and speed. Simple UI and fast answers matter more than flashy features.
Tips for Building Your Own RAG System
- Start small: Begin by indexing just a few high-quality documents
- Use frameworks: LlamaIndex or LangChain help avoid writing boilerplate for parsing and chunking
- Choose a scalable vector DB: Pinecone is reliable and scales well, there is also FAISS by Meta a good open-source alternative.
- Consider caching: Store popular queries to reduce costs, especially with GPT-4
- Implement feedback: Add user feedback mechanisms from day one
- Test with real users: Nothing beats actual user testing for uncovering edge cases